March 26, 2022
Identifying Potential Champions - IPL 2022
In my last post, we looked at how linear machine learning models can be trained to effectively predict a team’s score and win probability simply based on a small set of features. I was able to extend the same logic to the IPL by just modifying the data source - Cricsheet also provides ball-by-ball data for every game in every IPL season from 2008 till date - and observed very similar performance levels during evaluation.
In this post, however, the main goal is slightly different. The idea is to try and identify the teams that have the best chance of winning this year’s tournament using data from the previous year, i.e., if \(x_i^t\) is the data associated with team \(i\) in season \(t\), then the goal is to compute the probability (\(p_i^{t+1}\)) of team \(i\) winning the title in season \(t+1\) such that:
\[\begin{aligned} p_i^{t+1} = f(x_i^t) \end{aligned}\]For example, the probability that defending champions CSK will win the IPL again in 2022 is calculated as a function of their data in 2021:
\[\begin{aligned} p_{csk}^{2022} = f(x_{csk}^{2021}) \end{aligned}\]The decision to use this type of mapping is based on the fact that there have been quite a few instances where a team finishing a season strongly has won the title in the following season. After MI dramatically qualified for the playoffs in 2014, they went on to win their 2nd title in 2015. Similarly, CSK despite having their worst ever season in 2020 still managed to win three in a row at the end and were able to carry that momentum into 2021 to secure their 4th title.
Having discovered such patterns, I was curious to see if my hypothesis that there is indeed a strong connection between performances in one season and the next was true for a larger set of teams and across multiple seasons. It was also a great opportunity to try and experiment with the popular XGBoost library.
Data compiled manually from various sources is used for this experiment and teams that were not a part of the following season at any point are not included. What each of the columns represent is self-explanatory in most cases but there are a few that might seem unclear. For example, final_position corresponds to a team’s position after the knockout stage whereas position refers to their position in the points table.
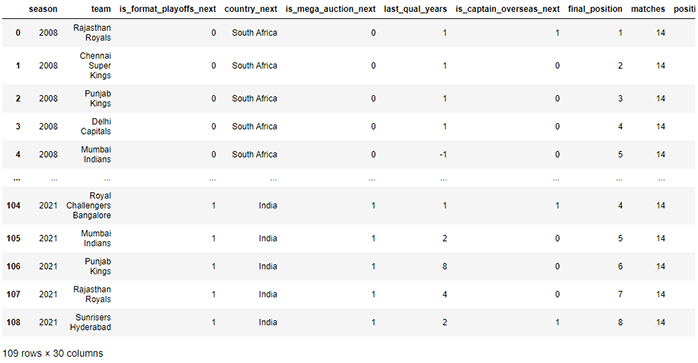
Preview of the dataset
Additionally, the “winless” in longest_winless_streak is slightly different from “losing” since the streak is not considered to be broken even if there are washed out games in between and last_qual_years refers to the number of years since the team last qualified for the playoffs with a 1 meaning that they qualified in that particular season whereas a -1 means that they never qualified previously.
The last three columns (final_position_next, in_next_playoffs, is_next_champion) correspond to target variables that can be used for different purposes. For this experiment, is_next_champion is the only one required and the other two are excluded from calculations. Nominal features are also not included since there does not appear to be any quantitative benefit in keeping them and they only seem to increase the dimensionality of the data in this case.
Numeric features such as wins, losses, points, etc. are divided by the matches column which serves as a normalizing factor and ensures that every value is on the same scale. This is done so that the 2012 and 2013 seasons where each team played 16 matches each (as opposed to the usual 14) can also be taken into account. After this step, matches is excluded from model training.
match_data_features = ['wins', 'losses', 'nr', 'points', 'longest_winning_streak', 'longest_winless_streak']
X[match_data_features] = X[match_data_features].div(X.matches, axis = 0)
match_data_features_2nd_half = list(map(lambda x: x + '_2nd_half', match_data_features))
X[match_data_features_2nd_half] = X[match_data_features_2nd_half].div(X.matches / 2, axis = 0)
X = X.drop(columns = 'matches')
Data from the first 10 seasons (2008-2017) is used for training and the rest is used for testing which is roughly equivalent to an 80-20 split. Before training, another important step is to compute the value to be set for the scale_pos_weight parameter in the XGBoost classifier which is required to handle class imbalance.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 24, shuffle = False)
class_weight = data.is_next_champion.value_counts()[0] / data.is_next_champion.value_counts()[1]
An additional thing to consider while building an XGBoost model is finding the best set of values for all the hyperparameters involved. GridSearchCV is one method that enables us to do this and it essentially creates a grid of all possible combinations and goes through each of them to find the set that gives the best result. The running time, however, can be very slow despite guaranteeing the optimal outcome.
An alternative is to use RandomizedSearchCV that searches the grid and picks one set of values at random. This can be repeated several times till the result obtained is deemed acceptable. Running this is significantly faster than exhaustive grid search but it could potentially lead to a sub-optimal result.
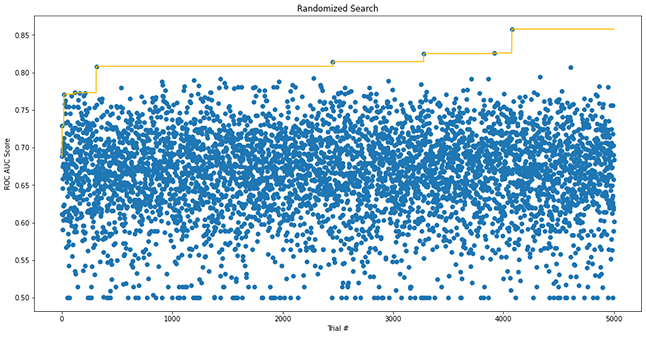
Randomized search with the best cross-validation ROC AUC score tracked over 5000 trials
Another popular option is to use a library such as Hyperopt. This works based on Bayesian optimization which means that instead of searching the grid randomly, it adjusts the search direction depending on whether it sees any improvement. So, at each step, it makes informed decisions using a probabilistic approach and hence is more likely to lead to an optimal outcome like with grid search while also not taking too much time like with randomized search.
Running Hyperopt is pretty straightforward: it just requires an objective function that returns a value that needs to be minimized (or the negative of a value that needs to be maximized) and a search space that defines the range of values that the optimizer needs to consider for each hyperparameter. Once this finishes executing, it returns what it thinks is the best result and this can then be used to re-define the model.
trials = Trials()
best_params = fmin(fn = objective, space = space, algo = tpe.suggest, max_evals = 100, trials = trials)
model = XGBClassifier(use_label_encoder = False, eval_metric = 'auc',
colsample_bytree = best_params['colsample_bytree'], gamma = best_params['gamma'],
learning_rate = best_params['learning_rate'], max_depth = int(best_params['max_depth']),
min_child_weight = int(best_params['min_child_weight']), n_estimators = int(best_params['n_estimators']),
reg_alpha = int(best_params['reg_alpha']), reg_lambda = best_params['reg_lambda'],
scale_pos_weight = class_weight, subsample = best_params['subsample'])
model.fit(X_train, y_train)
XGBoost also provides a convenient function to plot the features that are most important when building the decision trees. This information can be used to not only get an idea of what the model focuses more on while making predictions but also figure out which features can be dropped (if required) with little to no impact on model performance.
plot_importance(model, importance_type = 'gain', show_values = False)
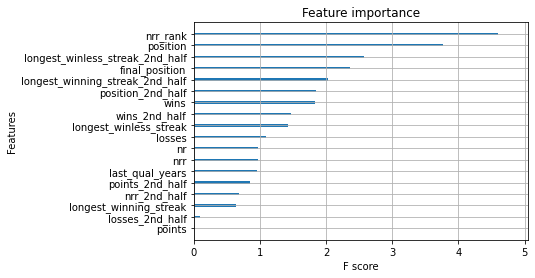
Feature importance plot for the XGBoost classifier
For evaluation, the set of three metrics used in the last post are used here as well: ROC AUC, confusion matrix, and classification report. The measures for the “champions” class are not great but not bad either since multiple teams might show title-winning traits but only one can ultimately win. The model does, however, appear to be very good at identifying the teams that will not be champions in the following season.
metrics.RocCurveDisplay.from_predictions(y_test, y_pred)
metrics.ConfusionMatrixDisplay.from_predictions(y_test, y_pred, normalize = 'true', cmap = 'Blues')
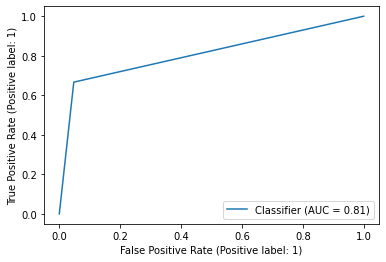

ROC AUC and confusion matrix for the XGBoost classifier
To best summarize the results for the 2022 season, a custom color map is used to provide a simplistic visual representation. From the test set predictions, optimal thresholds based on the best F-1 score and the minimum win probability for playoff qualification help in achieving this.
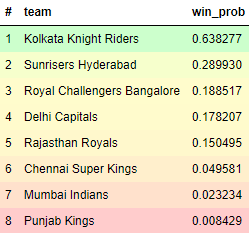
Probability of winning IPL 2022 for each team that took part in 2021
This suggests that, among the 8 teams that played in 2021, KKR are the favorites to win the title this year. One of the 2 new teams winning is a possibility as well but there is no past data available to compute their probabilities. The presence of such unknowns makes it a bit harder to predict but while the model may not be able to say exactly which team will win, it still does a good job of narrowing it down from 8-10 teams to just 2-3.
Furthermore, mega auctions that take place once every 3-4 years often lead to major changes to each team’s squad and this can also significantly affect predictions. A deep learning approach which additionally considers player profiles might be a potential solution but the computational cost of this entire process will have to be determined first before implementing such a model.
The full code for this project can be found here.