May 24, 2022
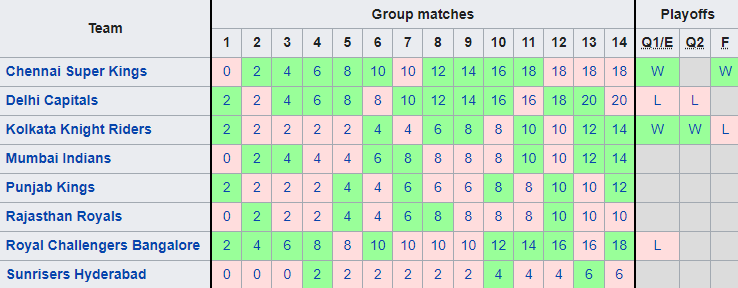
Road to the Playoffs - IPL 2022
With the league stage done and dusted, only four teams remain in the race for winning this year’s IPL and three of those are aiming to win their first title. Moreover, it is only the second time that just one from the preceding season’s top 4 has qualified for the playoffs whereas every other year (apart from 2016) has always had 2-3 from the previous set.
In my last post, we tried to identify the title contenders based on the previous season’s data. The goal in this one is to expand on that and use the information that we have from the start of the tournament up to this point (“the road to the playoffs”) to predict which team is most likely to win the big prize from here.
A few weeks ago, while I was going through the Wikipedia pages of past IPLs, I found the “Match summary” sections quite intriguing. It was a great way to quickly comprehend which teams did well at different stages thanks to the nice visual representations of the results. This made me wonder if the concepts from sequence classification using LSTMs could be applied to solve the problem in this post as well.
Match summary - IPL 2021 (source: Wikipedia)
Progressive data from 2011 - 2021 is collected from multiple sources and in addition to points, other features such as NRR, longest winning/winless streaks, number of unique player of the match award winners, etc. are also included. Only the years in which teams played 14 matches each are taken into account in this dataset and 2012 - 2013 are not present.
Information about whether a team finished in the top 4 or top 2 is available but this is excluded on purpose to see if the model can identify such properties by itself. Team names and the corresponding years are left out as well and the is_champion feature is chosen as the target. All samples except those for the current season are then considered for the input/output split.
num_teams_new = 10
matches_per_team = 14
num_samples_new = matches_per_team * num_teams_new
X, y = data.iloc[:-num_samples_new, 2:-3], data.iloc[:-num_samples_new, -1]
The next step is to split the data into train/test sets. This is done so that three out of the nine seasons are used for testing and the rest are used for training, making it a 67-33 split. It is important to note here that setting shuffle to true will not shuffle the timesteps within a sample/batch but doing this still makes no sense since the model could end up learning from future data for predicting on data from the past.
test_seasons = 3
teams_per_season = 8
test_size = test_seasons * teams_per_season * matches_per_team
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = test_size, shuffle = False)
Additionally, since every sample corresponds to one team, the target variable for each timestep in a sample remains the same. This means that these targets can be reduced to a single value corresponding to the whole sample instead because the goal in this post is to classify teams based on their entire sequence of 14 games and not after each game that they have played.
y_train = y_train.groupby(y_train.index // matches_per_team).apply(lambda x: x.mean()).reset_index(drop = True)
y_test = y_test.groupby(y_test.index // matches_per_team).apply(lambda x: x.mean()).reset_index(drop = True)
A simple architecture is implemented for the model which just contains three layers: an input layer to feed the samples into the network, an LSTM layer with 32 memory units and recurrent dropout, and an output layer for binary classification. The learning rate is slightly reduced from the default 0.001 and ROC AUC is chosen as the evaluation metric while training.
model = Sequential()
model.add(Input(shape = (matches_per_team, num_features)))
model.add(LSTM(32, recurrent_dropout = 0.2))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = tf.keras.optimizers.Adam(learning_rate = 1e-4),
metrics = [tf.keras.metrics.AUC()])
The last 20% of the training samples is set aside for validation which roughly corresponds to one out of the six seasons and the early stopping callback monitors the loss observed in this set. It then halts training as soon as this stops decreasing and restores the weights for the best loss.
history = model.fit(X_train, y_train, epochs = num_epochs, batch_size = batch_size,
class_weight = class_weight, validation_split = 0.2, callbacks = [early_stopping_monitor])
The ROC AUC score and the loss are plotted after every epoch for both the training and validation sets and the directions of both lines in these plots suggests that the model is able to generalize well. There, however, appears to be a larger gap between the two in the loss plot and this could be because the validation set might contain easier cases to predict or due to other reasons.
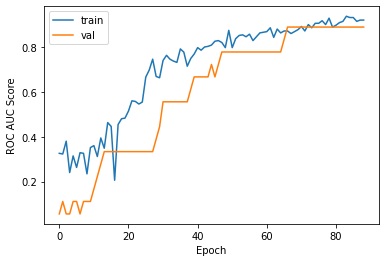
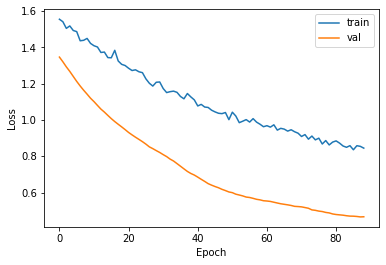
ROC AUC and loss plots for the LSTM model
The ROC AUC score for the test set is 0.9206 which is almost identical to the train set score of 0.9261 and shows that the model is able to produce similar performance levels while predicting on data that it never utilizes at any point in the training process. It gets one wrong but the top 2 predictions for each season cover all the champions in the test set and the minimum win probability among the three winners can be treated as a threshold for the 2022 predictions.
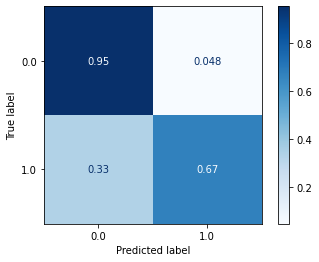
Confusion matrix for the LSTM model
The final model is trained on all the available data for the same number of epochs at which early stopping occurred during evaluation and the rest of the parameters remain the same as well. This is then used to predict on the 2022 samples from the dataset and the threshold mentioned above helps in visually separating the teams.
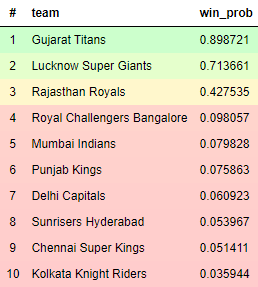
Probability of winning the IPL 2022 playoffs for each team
From this, it appears to be quite confident that Gujarat Titans will win this year’s title with LSG as second favorites and RR as dark horses. An interesting observation is that it thinks RCB’s probability is just marginally higher than that of teams who did not qualify and is close to 0. This could be because they somehow managed to qualify despite having the third lowest NRR in IPL knockout stage history.
If every result in the playoffs is predicted using this probability table, it would look something like the following image with GT expected to beat LSG in the final.
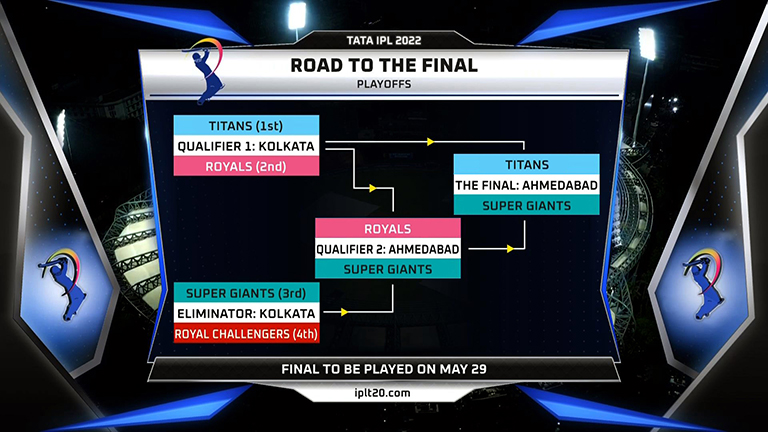
Road to the final - IPL 2022 (original image source: Twitter)
These results look promising but it is a little difficult to draw definitive conclusions from this since the dataset only contains 74 teams from nine seasons. This is also the reason why stricter early stopping is used to ensure that the model is not trained longer than necessary and allow it to make slightly more conservative predictions so that it is better equipped to handle potentially harder cases in the future.
An additional application of the ideas presented in this post is to use this as a starting point for building a live tournament predictor where the probabilities change match after match in the league stage. This would present another challenge as it requires handling sequences of variable length but it would still be a fascinating way to further enhance the viewer’s experience.
The full code for this project can be found here.